 |||
|||

I've been exploring the potential of the pix2pix system for generating photos from abstract representations of objects. A popular version of this currently buzzing around the internet is edges2cats, because cats, and more interesting work is being done by Mario Klingemann.
The basic principle is fairly simple. You create a pair of images. One is the original image and the other is an abstraction, usually an outline. You then train a neural network to try to generate the original from the abstraction. This is analogous to teaching a child to recognise dogs. You show it lots of pictures of different dogs labelled "dog" and eventually the child will correctly identify a dog even if it's never seen that specific dog before.
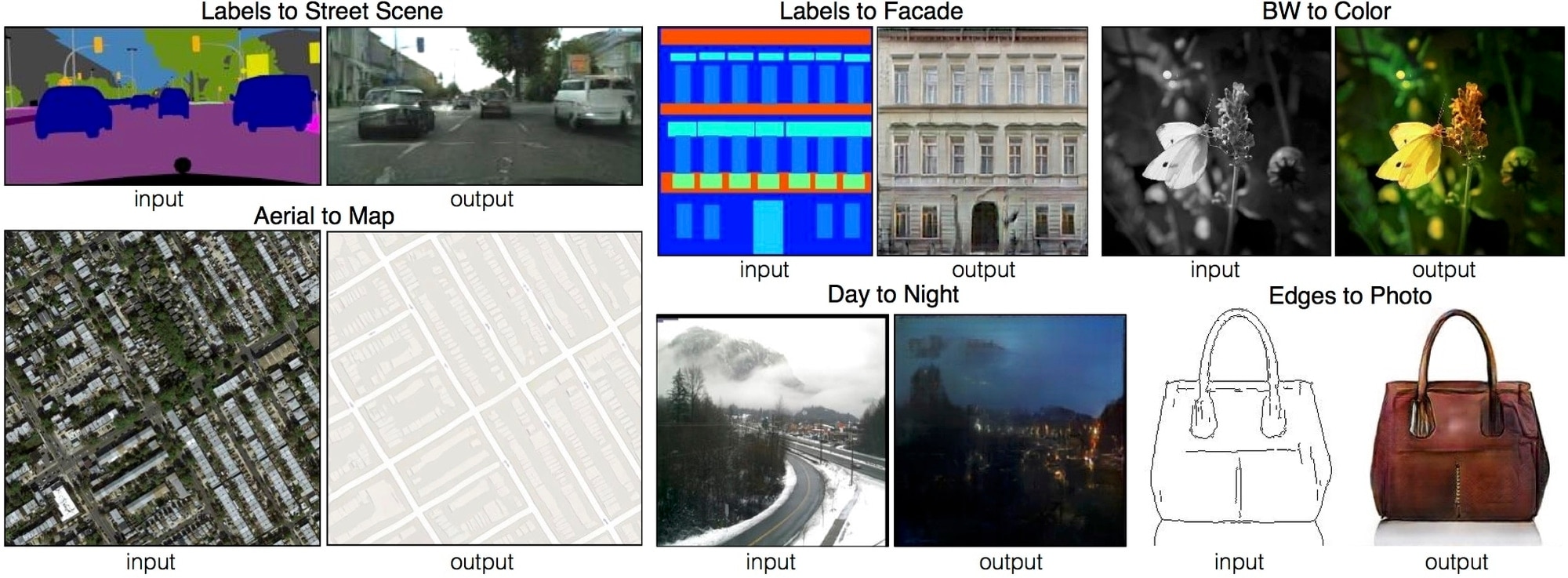
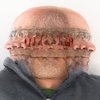
Once you've trained the system, you can then give it abstractions and ask it to figure out the "original". In theory it produces something that looks real, which is the goal of these systems. In practice it's very easy to produce something that looks weird and interesting, which is why artists have latched on to this stuff.
As well as the joy of producing weird images, I'm interested in exploring what's actually happening in these systems by poking them with sticks. I was drawn to Mario's use of blurred abstractions to create an oil-paint effect and wondered what other sorts of abstractions could be used. Since some of my work has involved transforming between mediums (image to sound, etc) I thought I'd give ASCII Art a try.
I used a collection of "classic photography" I'd found a while back as my training data and produced ASCII versions of each picture using the process included in Apple's Automator app. Here's an example.

The ASCII here is quite fine and uses all the possible characters, which wasn't giving me the abstraction I needed, so I went with jp2a which gave me a lot more control. Specifically I could up the font size and chose which characters it used. By limiting it to lower-case a-z and select punctuation I was able to generate this:

Now the abstraction looks closer to real text, the sort you might get in a book that makes sense. This is what I was after.
With the training underway I started to prepare my input for the final piece. I needed a body of text and settled on the Gutenberg edition of Oscar Wilde's The Picture of Dorian Gray because one should always go for the pun, but any text would do. I removed all paragraphs and extraneous spacing and exported it into squares which resembled the generated ASCII art. Here's the first page.

Once the training had finished processing overnight (it's a long process, though my electricity usage plug says it only cost 24p for 12 hours, which isn't bad) I asked it to generate photos from all 91 pages. Here's that first page again.

And here's all the pages in a video:
You can also download it as a PDF if you like.
Much more to be done, which is why this is a blog post and not on my Art website yet. Onwards!
