 |||
|||
I am sitting in a room at Aston University. It has bare white walls and work-benches with electricity and data sockets. On one wall is a digital projector and a whiteboard. It's otherwise empty. This is the Lab for ALICE, the AI team at the computer science department here. During term time it's busy but for the summer it's pretty much mine to do as I will.
Right now I'm trying to start. I know how I'm going to finish (with an exhibition in October) but the first steps are eluding me, so I've come here with a laptop and some whiteboard pens to make a stab at it. This blog post is recording that.
On Friday I had a big session with Emily Warner, one of the two performers I'm collaborating with for Instructions for Humans. This was mainly for us to get a more thorough sense of each others work and processes so that as I build the computational side of the work for her to respond to I'm doing so with her in mind. But it also helped to draw some threads together which I'd placed in very distinct silos in the initial outlines. It was great and very positive, but we covered a lot and it didn't always help with the starting.
One thing that did was a simple diagram which forms the basis for the whole piece. As an equation it could be written as:
Instructions for Humans informed by ModelLook, you have to start somewhere.
Emily has used symbols to represent movements in her Side-Effects piece and we'll initially be using these images as our basic instructions. They're appealing to be because they're quite organic shapes which could be represented as vectors, opening up a few possibilities for generating new ones.
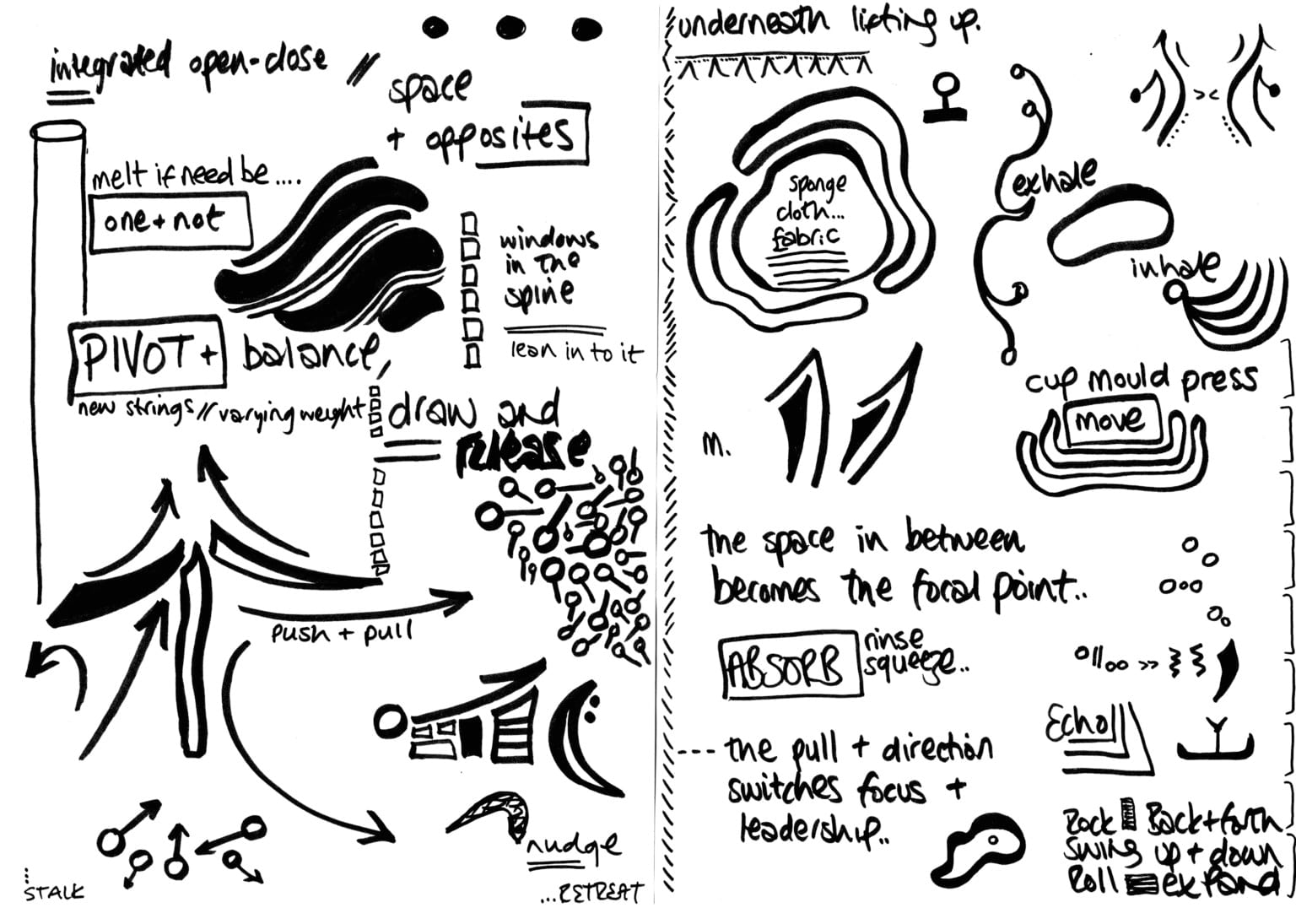
These shapes represent specific movements, so there's the concept there of a "matched pair". The pix2pix system uses training with matched pairs to generate new images from a new single image, so there's a framework here to work with. The issue here is there's not necessarily a visual similarity between the shape and the movement - the connection is something else, but representing abstract concepts connecting inputs and outputs is a (very important) problem for later.
And while these images by Kandinsky are beautiful, I don't want that sort of literal representation.

So, there's the Instruction which prompts a gesture or action from the Human. Now we need to bring in the Model.
A model, in machine learning jargon, is the data that is produced after training which is used to create outcomes from inputs. So a model trained on pairs of images where one is an outline and the other is a photograph will be able to create a new photo-style image from any drawn outline it is given. This is how edges2cats works.
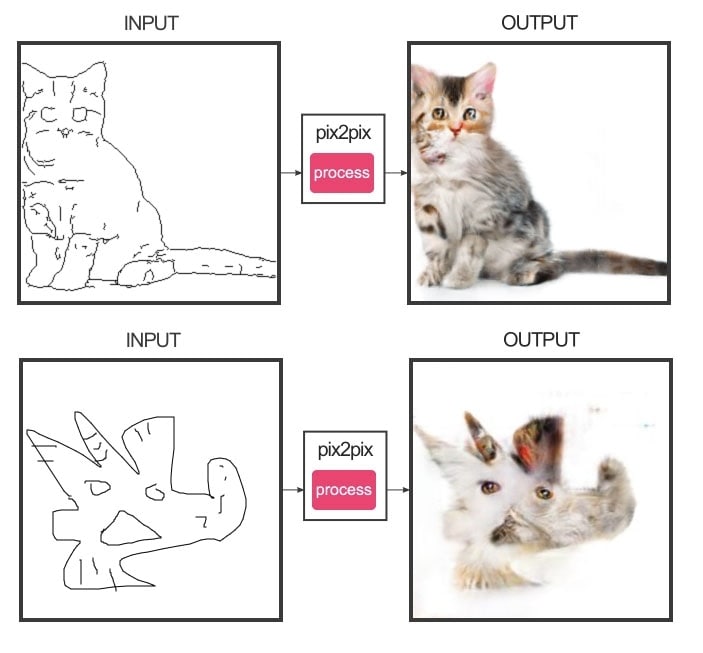
The model I'll be creating will be trained on "Birmingham" through an array of sensors and feeds supplying visual and other data. One major task is to use that data to inform the flow between instructional score and human performance. In Emily's work this role is taken by the space she's working in. It's not about slavishly turning the shape into a movement. It's about using the shape to guide and frame movement that is ultimately about the immediate environment.
Shape + Space = MovementIn this scenario, instructions aren't literal. They're not saying "turn three times on the spot and raise your hands above your head". They're not really "saying" anything at all. They should be thought of as suggesting a framework, a direction, an approach through which to engage with stuff, closer to the instruction "walk slowly and think about the sky", or maybe just "slow sky".
More accurately the instruction is "Look around you and 'slow sky'".
So within the system we're devising, Emily will be asked to respond to an instruction while aware of the model of Birmingham generated by the machine learning system. This could be as simple as having her perform by a projection of outputs from that system, and that's probably a good starting point. The system gives her a shape and an environment from which to create a movement.
There's a good starting point.
Next I need to deal with the following:
And plenty more besides!
Back at Aston on Wednesday. More then.